In the last part we went over the general ideas of Huffman coding as implemented in the newer Oodle Data coders, this time we’ll be looking at one particular implementation that is both interesting and “historically relevant”: Oodle was designed with games in mind, an important class of hardware to consider for game middleware is game consoles, and versions of the AMD Jaguar CPU were in both the PS4 and Xbox One (mostly unmodified except for a bump in clock rate in the “mid-lifecycle upgrade” models of both). We wanted Kraken to perform well on those machines, so we spent some time optimizing Oodle for it. Before I go into the details, let’s do a bit of background on the machine itself, but be advised that this will be in-depth and that you may need to re-read the previous part first. Furthermore, this post contains plenty of x86 assembly; if you’re uncomfortable or unfamiliar with that, you probably won’t get much out of it, sorry.
Meet the AMD Jaguar
The Jaguar, or less prosaically “Family 16h”, is a small, low-power, out-of-order 64-bit x86 CPU core designed for small systems and embedded applications such as, well, game consoles. In the game console variants, the Jaguar CPUs appear on the main SoC along with the GPU (and most other components). It’s designed for multi-core operation and cores usually appear in clusters of four that share a common L2 cache, usually 512kb of L2 per core. In the Xbox/PS4 versions, there are two such clusters and thus two L2 cache slices. This post is only concerned with tasks that run on a single thread so I won’t be spending time on this part of the architecture.
Each core has 32KiB of L1 instruction and 32KiB of L1 data cache. The frontend decode/dispatch/retire logic is 2 instructions wide, and the relevant unit for most of it is what is variously (depending on the source) called “macro-ops” or “cops” (complex ops), depending on the source. I’ll stick with macro-ops. Macro-ops are typically a data-processing instruction along with a memory reference, so something like the x86 instruction add rax, [rsi] would be a single macro-op.1 Macro-ops get broken into either one or two micro-ops (I’ll write uops in the following) for execution, but instruction decoding, tracking and retirement all works on macro-ops. The backend has six execution units, each of which can accept one micro-op per cycle: two integer (which I’ll refer to as I0 and I1), one load (L), one store (S), and two SIMD/floating point (which I’ll refer to as F0 and F1). The pipelines are very symmetric: almost all integer instructions can execute in either I0 and I1 (the biggest exceptions being multiplies and divides, which are I1 only), and most FP/SIMD instructions can execute in either F0 or F1 (FP addition and SIMD integer multiplication are only supported in F0, and FP multiplies and store/convert are F1 only). Consequently, most pairings of two independent instructions can execute in the same cycle, if they’re not both contending for the same resource. Of these backend limitations, in my experience the one you’re most likely to hit is the one load per cycle limit.
That said, whenever I’ve looked, the two instructions per cycle decode/dispatch limit is usually the more relevant one. On the Jaguars, using the load-operate and even read-modify-write instructions where possible is a good idea (because it gives you two uops per macro-op), and generally preferable to splitting loads out.
Speaking of loads, the L1 data cache is 8-way associative, write-back, and internally splits 64-byte cache lines into 16-byte sectors. Unaligned loads and stores that stay within a single sector are free, crossing a sector boundary occupies the load/store pipes for an extra cycle (potentially more if it also crosses a page boundary etc.). The load-to-use latency for the L1 data cache is 3 cycles to the integer pipes, 5 cycles to the FP/SIMD pipes, both of which are quite low numbers compared to most of its contemporaries.2 The theme of low latencies continues for other parts of the backend: FP32 multiplies and SIMD integer multiplies complete in 2 clock cycles, FP32 and FP64 adds in 3, and most SIMD ALU operations take a single cycle. L2 misses take relatively long though, at a minimum load-to-use latency of 25 cycles.
Lots of console developers found these cores underwhelming, mostly due to the narrow design and fairly low clock rates (around 1.6 and 1.7GHz in the original PS4 and Xbox One, respectively). On the other hand, these cores are quite small, power-efficient, and the PS4/Xb1 console generation came with 8 of them, at a time when more than 4 cores was a rarity in the consumer space. Personally, I quite like them: they’re not the fastest but what they are is extremely even-tempered and predictable. They have a relatively low ceiling on the instructions per cycle and peak performance they can achieve, but getting there is generally a fairly straightforward process, and there’s not much in the way of gotchas or nasty surprises. They’re a pleasant core to optimize for3, and AMD helped by providing good documentation for it.
The Plan
Because of the aforementioned decode/dispatch/retire limits and low instruction latencies, optimizing code with reasonably nice memory access patterns for the Jaguars is, more often than not, an exercise in minimizing number of instructions executed for a given task. (As I said, they’re fairly straightforward to optimize for!) Therefore, if we want a fast Huffman decoder on these machines, it’s a good idea to see if we can do it with as few instructions as possible.
While reviewing the above-quoted docs, one thing I noticed was that BEXTR, an instruction from BMI1, turns into one uop, is supported on both integer pipes, and has 1-cycle latency. BEXTR is an odd duck: it extracts a given number of bits from a given starting point in the first source operand, and as such is essentially a counterpart to PowerPCs rlwinm or ARMs UBFM, but while these latter two instructions have the bitfield position and width given as an immediate operand, BEXTR takes a register operand for the bitfield specification.4 Code that wants to do repeated bitfield extraction with the same operands can burn a register on a constant (itself a fairly steep cost on the relatively register-starved x86) and then use BEXTR, which replaces a move, shift, and an bitwise AND instruction.5 The second source register operand to BEXTR contains, itself, bit-packed values: the lower 8 bits give the index of the LSB of the bitfield to extract, the next 8 bits give the width in bits.
This is usable for the bitstream decoding part of our Huffman decoder. Using a “bit extraction” style decoder (variant 3 in this post) means we repeatedly do operations of the form (bit_buf >> bit_pos) & ((1 << 11) - 1)) to peek at our next 11 bits, and that is just BEXTR(bit_buf, bit_pos + (11 << 8)). It doesn’t cause any problems to have a constant bias that shows up only in the high bytes added to our bit position, so we can just declare our bit positions to have that offset added at all times while in registers, and that lets us do our bit buffer peek in a single 1-uop instruction on Jaguar cores. Because of another x86 quirk, namely that byte-sized instructions exist and preserve the remaining bits of the register, we can do updates of bit_pos using byte-sized additions or subtractions that leave the high bits alone, if we want to.6
Finally, we don’t want to do a store for every byte we decode, because that’s an extra instruction and we’re easily limited by instructions (or rather, macro-ops) executed. Fortunately we can use the SSE4.1 instruction PINSRB (packed insert byte), which inserts a byte value from an integer register or memory into a given lane of a vector register. Vector registers hold 128 bits (16 bytes), which means we can amortize the number of stores and do one every 16 or so bytes instead of for every codeword. Finally, because Jaguar cores treat memory references inside an instruction as separate uops but not separate macro-ops, and macro-ops are one of our main limiters, we want to use memory references liberally if doing so lets us reduce the number of macro-ops we need.
Putting this all together, note that the pseudocode for the per-symbol processing in a LSB-first Huffman decoder, as outlined in the previous part, looks something like this:
// peek
uint32_t bits = (bit_buf >> bit_pos) & 2047;
// consume bits
bit_pos += table[bits].len;
// decode symbol
emit(table[bits].sym);
and using the various techniques outlined above, we can turn this into a mere 3 x86 instructions:
; peek. rBitPos[15:8] = 11
bextr rBits, rBitBuf, rBitPos
; advance bit offset (update low byte only)
add rBitPosb, [rTableBase + rBits*2]
; put table[bits].sym at position N into xmm0
vpinsrb xmm0, xmm0, [rTableBase + rBits*2 + 1], N
On the Jaguar, this decomposes into 3 macro-ops and 5 uops: 2 loads, 2 integer ops, 1 SIMD. The bit extract to grab rBits from rBitBuf takes a single cycle; the bit position update takes 3 cycles to load the value from the table and an extra cycle to complete the addition. We don’t actually care about the top bytes being preserved here, since we don’t expect overflows, but we do care about our load-operand being byte-sized. Either way, that’s 5 cycles critical path latency from one decoded symbol to the next. Finally, the vector byte inserts to collect the output bytes are not on the critical path. They need to be fast enough to keep up with our decoding bytes once the table loads finish (and they are, single they can complete at a rate of 1 per cycle) but that’s about it. With the Jaguar frontend supporting at most 2 macro-ops per cycle, this code takes at least 1.5 cycles per symbol decoded in the frontend, and 2 cycles per symbol decoded in the load pipeline. Meaning that as given, this code is limited more by the load pipeline than the frontend. However, this is not the only work that needs to happen in this loop, and the Jaguar is out-of-order, so we can build up a backlog of load pipeline work; if we later need to do more integer work in the loop that does not take many loads (spoiler: we will), the load pipeline will get to catch up.
Finally, as mentioned above, our critical path between back-to-back loads from the same stream is 5 cycles on the Jaguar. If we use 3 streams and interleave their processing during decode, then the frontend will get around to the first instruction for the second byte of stream 0 about 4.5 cycles in (although the load pipeline will take about 6 cycles to work through its backlog before then). In other words, the timing here can roughly work out, but it’s not perfectly matched; we will build up a bit of backlog in the load pipeline and the reorder buffer before this is done, but as long as we choose our instructions carefully and don’t go too lopsided, we can make this work while keeping the core nice and busy the whole time through.
I was pretty excited when I first realized this 3-instruction sequence was a viable candidate for the core of our Huffman decoder on Jaguar, but to get a real decoder we also need to deal with bit buffer refills, pointer advancing, and end-of-buffer checks.
The actual decoder
As mentioned above (and in the previous part), we use 3 separate bitstreams for parallelism. Of these, two bitstreams are regular “forward” bitstreams in increasing address order, and one is written backwards. The numbering of these is a bit odd: in the physical Oodle format, the layout is strm0-> | strm2-> | <-strm1, i.e. stream 0 is forward and comes first (as you would expect), stream 1 is backward and comes last, and stream 2 is also forward and somewhat awkwardly sandwiched in the middle, for “historical reasons”. Namely, Kraken uses forward-backward stream pairs in many places.7 The Huffman decoder used to be the same way; when we noticed (while working on this Jaguar decoder, in fact) that three streams would be advantageous, we had to put the third stream somewhere. Putting stream 2 in the middle turned out to be slightly easier.8 The advantage of the odd-looking backward stream is that it saves us a bit of signaling in the container format (not a trivial concern for a compression format) and also gives us a nice way to do end-of-buffer checks. Namely, the three are contiguous, and all three read pointers (called in0, in1 and in2 in the following) are in that single contiguous region. Furthermore, in0 keeps increasing, in1 keeps decreasing, and at any point in a well-formed stream, we have buffer_begin ≤ in0 ≤ in2 ≤ in1 ≤ buffer_end. During decoding, we do the two interior checks of the read pointers against each other; the end-of-buffer checks on either end are implied by transitivity, and we don’t need to actually do them, or keep those extra pointers around. The only pointers we need to check are the ones we already keep around anyway. Neat!
Now, loads aren’t zero-sized; we use the (common in C) convention that “end” pointers point one past the last element of arrays. So we don’t want to start loading from in1, and with 64-bit (8-byte) loads, the largest address we can ever safely load from is at buffer_end - 8, assuming the buffer is at least 8 bytes to begin with (which we check beforehand). Decrementing in1 by 8 before the loop takes care of both issues: now in1 points to the last address we can do a valid 64-bit load from, and as a side effect in0 ≤ in2 ≤ in1 ends up guaranteeing that in0 and in2 are also good to safely load 8 bytes from without overrunning the buffer. Finally, the optimized decoder loop described here decodes 5 bytes each from 3 streams and writes the results using a 16-byte SIMD store, so it can only safely run until 16 bytes before the intended end of the buffer. All the remaining special cases (less than 8 bytes left in some of the streams, very short input streams, or close to the end of the output buffer) are left to a dedicated safe loop that generally handles the last few bytes, needs to do more careful checking, and is certainly not using hand-tweaked assembly. There would be no point for speed since it only ever handles very few bytes, and besides that’s the exact loop where you very much want a higher-level language for better debugging facilities and good integrations with sanitizers, fuzzers etc.
With a plan for all those details, all we need to take care of now is the refill logic and sort out the remaining plumbing. Looking at the decoder sketch above, we see that we need at least 2 registers worth of state per bitstream: one register to contain bit_buf (rBitBuf in the pseudo-ASM), and one for bit_pos. Once we consider refilling, we also need the corresponding read pointer (the inN I was just taking about). For 3 streams, 3 registers of state per stream works out to 9 registers, a bit more than half of our general-purpose register name pool, which is workable.
As for refill, that is luckily straightforward in a “bit extract” style scheme. At the top of every iteration, we want to load the next 8 bytes from the current input pointer:
mov rBitBuf0, [in0]
For the reverse byte order in1 stream, we use a big-endian load (MOVBE) instead, which is the same cost as the regular load on the Jaguars.9
Then we decode 5 values from each of the 3 streams. With our 11 bits code length limit, that means we end up consuming at most 55 bits from each stream. Most relevant bit reading techniques support at most either 56 or 57 bits in a row without a refill when using 64-bit registers, so this fits well.10 Decoding 3×5 = 15 symbols also works out very nicely with our 128-bit vector registers, so we do a single unaligned vector store every 15 bytes.11
Finally, after each stream has decoded 5 symbols, we need to check how many bytes to advance the read pointer by, and what the new start position within the byte is. The number of bytes we need to advance the read pointer by is (bit_pos >> 3) & 7, which on the Jaguar, we can compute using a single BEXTR if we can afford a register just to store the constant 0x303, which we can.12 We then either add or subtract this from the corresponding in pointer. Finally, we need to clear the bits corresponding to the byte position (that we just took care of) in bit_pos, which is an AND by ~0x38. This keeps the high bits, containing the 11 bitfield length that we need, intact. The actual code below does this masking at the start of the next iteration instead of at the end of the current iteration, but conceptually this belongs with the pointer advance.
And that’s pretty much it. Here’s the full decoder loop, written in NASM. We originally tried to write this in C++ with intrinsics, but that got nasty, so we eventually switched to a real assembler. The original version has the comments laid out differently but I need to fit this into an annoyingly narrow blog CMS theme, so this will look a bit clunky:
; main decode loop
; rax = scratch
; rbx = bitextr0
; rcx = bitextr1
; rdx = bitextr2
; rbp = bextr const
; rsi = table ptr
; rdi = -bytes_left_to_decode
; r8 = in0
; r9 = in1
; r10 = in2
; r11 = bits0 (only live in inner loop)
; r12 = bits1 (only live in inner loop)
; r13 = bits2 (only live in inner loop)
; r14 = decodeend
; r15 = (unused)
sub r9, 8 ; in1 -= 8
mov ebx, 0xb00 ; 11 field width
mov ecx, 0xb00
mov edx, 0xb00
mov ebp, 0x303 ; for byte step
align 16
.bulk_inner:
; non-crossing invariant: in0 <= in2 && in2 <= in1
cmp r8, r10
ja .bulk_done
cmp r10, r9
ja .bulk_done
; refill stream 0
; read next bits0, keep bit offset within byte
mov r11, [r8]
and ebx, ~0x38
; refill stream 1
movbe r12, [r9]
and rcx, ~0x38
; refill stream 2
mov r13, [r10]
and rdx, ~0x38
%assign i 0
%rep N_DECS_PER_REFILL
; stream 0
; peek
bextr rax, r11, rbx
; consume
add bl, [rsi+rax*2]
; grab sym
vpinsrb xmm0, xmm0, [rsi+rax*2+1], i+0
; stream 1
bextr rax, r12, rcx
add cl, [rsi+rax*2]
vpinsrb xmm0, xmm0, [rsi+rax*2+1], i+1
; stream 2
bextr rax, r13, rdx
add dl, [rsi+rax*2]
vpinsrb xmm0, xmm0, [rsi+rax*2+1], i+2
%assign i i+3
%endrep
%undef i
; final advances
; num_bytes_step0
bextr rax, rbx, rbp
; in0 += num_bytes_step0
add r8, rax
bextr rax, rcx, rbp
sub r9, rax
bextr rax, rdx, rbp
add r10, rax
vmovdqu [rdi+r14], xmm0
add rdi, 15
; loop while bytes_to_decode > 0
js .bulk_inner
That’s the core 3-stream Huffman decoder loop. Time to quit it with the hand-waving and do an actual analysis (if only back of the envelope) to make sure we’re on the right track here.
Analysis
We already looked at the core decode step earlier and noted that it has 3 macro-ops (I’ll write 3M in the following), and for the backend: 2 integer 0/1 ops (just 2I for short), 2 load unit cycles for aligned loads (2L for short), and 1 FP/SIMD op (1F for short). We do this 5 times per stream. Also per stream is the refill/advance logic, which we now know the instructions for: 1 load for the refill, and 3 integer ALU ops for the byte advance and bitpos update. The load in the refill is almost always unaligned, though. It’s a 64-bit load, and as noted in the introduction, unaligned loads are free if they stay within an aligned 16-byte sector, and cost at least 1 cycle extra when they don’t. Out of the possible load offsets mod 16, 9 (0 through 8 inclusive) stay within a 16-byte sector, the other 7 do not. That’s 7/16=0.4375 odds of at least one cycle extra, and some of those cases (such as crossing cache lines and pages) get more expensive than just adding a cycle. For sanity in the following, let’s just say that we bake this all down to somewhat simpler numbers and expect around 1.44 cycles average case (but probably closer to 1.5 in realistic conditions) for those unaligned refill loads, 2 cycles for a much more pessimistic estimate. In other words, we want to bill the unaligned refill loads at costing more than single aligned load, since the expected number the load pipelines are occupied with them is larger.
Taking that into account, the four instructions involved in refill and advance for a single stream boil down to 4M, 1.44-2L, and 3I.
Then, we have some cross-stream shared instructions: the two compare/jump pairs for our pointer-crossing check at the beginning account for 4M 4I, the final store accounts for 1M 1.44-2S (since it’s also unaligned), and the final ADD/JS pair contribute another 2M 2I to the tally. That’s all instructions in the loop accounted for.
For an overall throughput estimate, we get:
- 15 × 3M (decodes) + 3 × 4M (stream refill/advance) + 7M (shared rest) = 64M total, so 64 macro-ops, enough to occupy the front-end for at least 32 cycles.
- 15 × 2L (decodes) + 3 × 1.44-2L (stream refills) = 34.3-36L total, so the load unit is busy for 34.3-36 cycles.
- 15 × 2I (decodes) + 3 × 3I (stream refills) + 6I (shared) = 45I total, evenly distributes over both integer ALU pipes for 22.5 cycles worth of pressure.
- 15 × 1F (decodes) = 15F total, distributed over both FP/SIMD pipes for 7.5 cycles worth of pressure, so they’re loafing.
- 1.44-2S for 1.44-2 cycles worth of pressure on the store pipe which I assume is sitting on the sidelines munching popcorn.
Purely in terms of pressure on the execution resources, we’re mainly limited by the load pipes which are busy for around 34.5-36 cycles every iteration, closely followed by the frontend which is occupied for at least 32 cycles if everything goes perfectly. 34.3-36 cycles to decode 15 bytes works out to 2.287-2.4 cycles per byte decoded. This is assuming we can ever get throughput-bound to begin with, and is budgeting absolutely no time for L1 cache misses and such.
How does the critical path look? By my reckoning, the most likely candidate takes a freshly updated in pointer from the end of a previous iteration, does an unaligned load to refill which takes 4 cycles for the data to show up, then does 5 back-to-back decodes from that stream which we know have a critical path latency of 5 cycles each, and then finally needs to do a BEXTR on the resulting bitpos followed by an integer add/subtract to produce the next load address. That’s 4 + 5 × 5 + 2 = 31 cycles of critical path latency through the stream decodes, worse if anything bad happens, like extra delays due to page crossings on a load or similar. 31 cycles is close enough to our other 2 limiters for it to be considered a 3-way near-tie. A hitch in the front-end or load pipes or any extra delay along the critical path is likely to end up delaying any given iteration if it occurs. Note I’m purely looking an ideal throughput estimates here, there is no modeling or simulation of machine details going on, all we’re doing is tallying up some figures based on known machine characteristics.
In short, from this rough estimate, we would expect somewhere around 2.3-2.4 cycles per byte for this decoder under very idealized circumstances where there’s not a single cache miss or hitch anywhere along the way, and “a bit worse” (to be decided what that means) when less idealized.
The rubber hits the road
So what happens when we actually run it?
One of the nice things about coding for game consoles is that the hardware is known and tends to have very predictable, repeatable performance. With that said, here’s stats for the exact loop quoted above running on a PS4 on a synthetic test set (decoding a random stream with a very boring “every symbol is 8 bits” Huffman table, which of course you’d never do, but makes for a test run that’s very easy to validate the results of) 1000 times, and reporting 1st, 50th (median) and 95th percentile cycles per byte:
huff3_jaguar_asm: med 2.28/b, 1st% 2.25/b, 95th% 2.38/b
I swear I did not fudge this in any way, that’s the actual figures I got on a real test run just now. So that much, ahem, very encouraging, to say the least. But what happens when you time it in the middle of an actual Kraken decode of ~250MB of real non-synthetic test data?
SimpleProf :seconds calls count : clk/call clk/count
get_array_huff : 0.3879 17689 178617138 : 34946.1 3.46
huff_x64jaguar_loop : 0.3035 31350 178617138 : 15427.6 2.71
Here get_array_huff includes everything the Huffman decoder has to do, including reading the headers, the Huffman table descriptions, validating the code lengths, setting up the tables, the fast decode loops, and the slower near-end-of-data tail decoders, and huff_x64jaguar_loop is just the core optimized decode loop that handles most of the bulk data. “Calls” is the number of calls to either function and “count” is the number of bytes decoded. In this case, 250MB of data “only” decode about 178MB through the Huffman decoders; less than 250MB because we also do LZ-style dictionary compression (not covered in this series). So in this particular real-world use case (which very much does not have all the buffers already nicely in the L1/L2 caches as it’s running), we’re about 17% slower than our ideal average-case throughput estimate for this loop, which is still respectable. Also visible from these two lines is that the core decode loop where around 75-80% of the overall Huffman decoding time is spent with the rest being in setup or tail handling. That is fairly typical for our decoder implementations on various platforms. And you can infer from the figures given that our average array of bytes that use a single Huffman table is about 10k long. For this part, looking at averages is misleading: the distribution is quite wide. Many arrays are 60k+, but many others are well below 3k. The former spend more time in the core decoder (always nice since that part is flat), the latter spend a lot more time proportionately in header parsing and table initialization, which is why we can’t neglect it.
This last part is also why the Jaguar decoder (or, for that matter, all other decoders in Oodle) doesn’t bother with trying to set up tables to decode multiple symbols at once. This sounds enticing but it makes table setup more complicated and slower, and also adds many complications to the decoders because everything emits a variable number of bytes now. For example, using PINSRB to group output bytes would not work if each decode step produce either 1 or 2 bytes; we would need to do individual stores for every symbol, and also increment the destination pointer after every decode. This would add at least 2 instructions per byte decoded (a store and a destination pointer add), probably more. When your single-byte-at-a-time decode kernel runs 3 instructions per byte to begin with and instruction count is a major limiting factor, adding 2 extra more instructions to maybe decode 2 bytes at a time isn’t all that tempting. We can decode another byte in an extra three instructions with the single-byte-at-a-time decoder guaranteed, and we don’t need to do any expensive extra work during table setup to do so. We also don’t build up a debt of 2 instructions every time we don’t manage to decode 2 symbols at once that we later have to make up just to break even. Multi-symbol decoding is an old standby when decoding from a single stream, because you can hide a lot of extra work in the shadow of that nasty long critical path, but decoding from multiple streams simultaneously gives you more productive ways to spend those CPU cycles and maybe even get to the holy grail of being primarily throughput bound.
And that’s all I got for this post! I’m not sure which of the other decoder variants I’ll tackle next. Apologies for the long delay, but writing these up takes more effort than my usual blog post, and I need to be in the right headspace to even try doing it.
Footnotes
[1] If you’re familiar with Intel microarchitectures but not AMD, macro-ops are roughly comparable to what Intel calls “fused-domain micro-ops”, except they’re “even CISCier”, in the sense that even read-modify-write instructions like add [rdx], rax count as a single macro-op, where Intel would split them into a add-from-memory and a store internally. I’ll also add that historically speaking describing AMD macro-ops as similar to Intel fused-domain uops is backwards; AMD has been using “fat” macro-ops as part of their x86 instruction decomposition for a long time, since at least the K7 (original Athlon) architectures. Intel added fused micro-ops (which are more restricted) years later to their microarchitectures when they realized that having the frontend deal with these “chunkier” units was beneficial.
[2] Typical L1D load-to-use times for contemporary designs were 4 or 5 cycles. For that matter, they still are at time of writing, 9 years after Jaguar-based HW hit the shelves. That said, the Jaguars target much lower clock rates than those other designs—the fastest Jaguar descendants ran a bit above 2GHz, other OoO x86 cores from the same timeframe have similar L1D sizes and were typically designed to hit 4GHz or above, so presumably the Jaguar cores can fit a lot more logic into a pipeline stage.
[3] To editorialize even more, the Jaguar’s nearly complete lack of sharp edges and huge performance cliffs was a welcome change after the PS3/Xbox 360 generation, where the main CPU cores seemed at times like they had nothing but.
[4] Presumably due to a problem with the way immediate operand encoding in x86 works. Specifying a bitfield position and width needs at least 6 + 6 = 12 bits to be generally useful on a 64-bit machine. But x86 immediate operands for instructions with 32- or 64-bit operands only come in two sizes: 8 bits and 32 bits. The former is not enough, the latter is very wasteful. 16-bit immediates only exist for 16-bit register instructions, and this part of the encoding would be quite expensive to add exceptions to. Interestingly AMD added a short-lived immediate-operand version of BEXTR that indeed spends a full 32 bits, but this version of the instruction decodes to 2 macro-ops on Jaguar and was removed from Zen 3. It never shipped on any Intel CPU.
[5] All “big core” Intel CPUs that support BEXTR (that I’m aware of, anyway) decode it into 2 uops. The same CPUs can usually eliminate register-register moves during register renaming and would also take 2 uops for a shift-and-mask combination, so BEXTR has never been particularly interesting on them, since it offers at best some minor advantages in the frontend. It’s more interesting on the Intel Atom-derived cores such as the Alder Lake E-cores (which like Jaguar have a 1 uop, 1 cycle version) and AMD Zen cores, though.
[6] Yet another AMD/Intel difference: Intel has been renaming the 8-bit parts of registers such as AL and AH of RAX or R9B of R9 separately for a long time, meaning AL and AH can reside in separate locations in the physical register file. When referencing the merged halves as a single register (such as AX, EAX or RAX) later, Intel CPUs used to either stall (the “partial register stall” of long ago) or, later, started inserting merge operations that combined the results into the instruction stream. AMD has never done this, and instead seems to do partial updates on every operation. That means that on Intel CPUs, code that alternately updates AL and AH can execute as two independent dependency streams, whereas on AMD CPUs all these updates run in series. However, AMD never needs to insert any merge ops either, and has no special penalty for referring to the full register after a partial update, which is handy in our use case: on the Jaguar we’re always concerned with macro-ops through the front-end, so injecting merge operations would suck for us. Good that we don’t get any!
[7] Two streams so that we can alternate decoding from them, because (as seen in this post already and also mentioned in previous parts) sequential decoding from a single bitstream tends to result in very long dependency chains and is a bottleneck. Having pairs of forward and backwards streams with the two meeting in the middle allows us to store a single size in the bitstream to signal the start position of the reverse stream and the combined size as a single value. They also can, in some contexts, act as padding for each other. During decoding, ensuring the pointers don’t cross corresponds to a end-of-buffer check; we don’t know the exact size of either stream up front, but we know that the read pointers may never cross, and once decoding is done they should point to the same location.
[8] Arguably, we should have at least renumbered the streams and swapped labels of streams 1 and 2; but as is often the case, this was quickly prototyped, found to be working, then for a while we were concerned with other things such as buffer overflow safety and such, and by the time we realized it was pretty odd for stream 2 to appear in the bitstream before stream 1, it had long shipped to customers and was very much not worth a format-breaking change to rectify.
[9] Very convenient how the bitstream layout chosen works out so nicely for the most constrained of the important target platforms for Oodle.
[10] Yet another very-much-not-a-coincidence.
[11] This one actually is a coincidence, but I’ll take it.
[12] Yes, the decoder loop keeps 0x303 pinned in a register the entire time it’s running. Long-time friends will realize why this delights me; sometimes the universe just smiles at you like that. This one’s for you, Felix.




 of n symbols numbered 0 to n-1.
of n symbols numbered 0 to n-1. := M \lfloor x/F_s \rfloor + B_s + (x \bmod F_s)")
 := (s, F_s \lfloor x/M \rfloor + (x \bmod M) - B_s)") where
where ") .
. is the frequency of symbol s,
is the frequency of symbol s,  is the sum of the frequencies of all symbols before s, and
is the sum of the frequencies of all symbols before s, and  is the sum of all symbol frequencies. Then a given symbol s has (assumed) probability
is the sum of all symbol frequencies. Then a given symbol s has (assumed) probability  .
. -bit unsigned integer by a constant can always be performed as fixed-point multiplication with a reciprocal, using
-bit unsigned integer by a constant can always be performed as fixed-point multiplication with a reciprocal, using  bits (or less) of intermediate precision. This is exact – no round-off error involved. Compilers like to use this technique on integer divisions by constants, since multiplication (even long multiplication) is typically much faster than division.
bits (or less) of intermediate precision. This is exact – no round-off error involved. Compilers like to use this technique on integer divisions by constants, since multiplication (even long multiplication) is typically much faster than division. requires some extra work; details are explained in the code.
requires some extra work; details are explained in the code. to the corresponding symbol index. In normal rANS, each symbol covers a contiguous range of the “slot index” space (by contrast to say tANS, where the slots for any given symbol are
to the corresponding symbol index. In normal rANS, each symbol covers a contiguous range of the “slot index” space (by contrast to say tANS, where the slots for any given symbol are  steps (remember that n is the size of our alphabet) from the cumulative frequency table (the
steps (remember that n is the size of our alphabet) from the cumulative frequency table (the  , which take O(n) space) – independent of the size of M. That’s comforting to know, but doing a binary search per symbol is, in practice, quite expensive compared to the rest of the decoding work we do.
, which take O(n) space) – independent of the size of M. That’s comforting to know, but doing a binary search per symbol is, in practice, quite expensive compared to the rest of the decoding work we do.") space, at a cost of
space, at a cost of ") per symbol lookup; or we can use
per symbol lookup; or we can use ") space, with
space, with ") symbol lookup cost. Now what we’d really like is to get
symbol lookup cost. Now what we’d really like is to get  = (s, F_s \lfloor x/M \rfloor + (x \bmod M) - B_s)") where
where  - B_s") part is the number we need. Now with the alias method, the slot IDs assigned to a symbol aren’t necessarily contiguous anymore. However, within each bucket, the slot IDs assigned to a symbol are sequential – which means that instead of the cumulative frequencies
part is the number we need. Now with the alias method, the slot IDs assigned to a symbol aren’t necessarily contiguous anymore. However, within each bucket, the slot IDs assigned to a symbol are sequential – which means that instead of the cumulative frequencies  = M \lfloor x/F_s \rfloor + B_s + (x \bmod F_s)")
") is the slot id corresponding to the
is the slot id corresponding to the ") ‘th appearance of symbol s.
‘th appearance of symbol s.







 . Often, p=0 (“it’s certainly a 0″) and p=1 (certain 1) are excluded, because they only allow us to “encode” (using zero bits!) one of the two symbols.
. Often, p=0 (“it’s certainly a 0″) and p=1 (certain 1) are excluded, because they only allow us to “encode” (using zero bits!) one of the two symbols. such that
such that  for all
for all  and furthermore
and furthermore  . In practice, we will again represent them using integers. Rather than dealing with the hassle of having fractions everywhere, let’s just define our “finite-precision distributions” as integer vectors
. In practice, we will again represent them using integers. Rather than dealing with the hassle of having fractions everywhere, let’s just define our “finite-precision distributions” as integer vectors  , again
, again  where T is the total. Same as with the binary case, we would like T to be a constant power of 2. This lets us use cheaper variants of conventional arithmetic coders, as well as
where T is the total. Same as with the binary case, we would like T to be a constant power of 2. This lets us use cheaper variants of conventional arithmetic coders, as well as  and
and  while maintaining a total of T=8. Computing
while maintaining a total of T=8. Computing  = \begin{pmatrix}2 & 4.5 & 1.5\end{pmatrix}") illustrates the problem: the two non-integer counts have to get rounded back to integers somehow. But if we round both up, we end up at a total of 9; and if we round both down, we end up with a total of 7. To achieve our desired total of 8, we need to round one up, and one down – but it’s not exactly obvious how we should choose on any given symbol! In short, maintaining a constant total while mixing in this form proves to be tricky.
illustrates the problem: the two non-integer counts have to get rounded back to integers somehow. But if we round both up, we end up at a total of 9; and if we round both down, we end up with a total of 7. To achieve our desired total of 8, we need to round one up, and one down – but it’s not exactly obvious how we should choose on any given symbol! In short, maintaining a constant total while mixing in this form proves to be tricky.
![\lambda \in [0,1]](http://s0.wp.com/latex.php?latex=%5Clambda+%5Cin+%5B0%2C1%5D&bg=f9f7f5&fg=444444&s=0 "\lambda \in [0,1]") , then define:
, then define: P_j + \lambda Q_j, \quad 0 \le j \le n")
 \left(\sum_{k=1}^j p_k\right) + \lambda \left(\sum_{k=1}^j q_k\right)")
 p_k + \lambda q_k)")
") :
:
 and
and  where m is an arbitrary integer. Then we also have
where m is an arbitrary integer. Then we also have  .
. (P_j - P_{j-1}) + \lambda (Q_j - Q_{j-1}) \ge (1-\lambda) m + \lambda m = m")

 + b \rfloor - \lfloor \tilde{R}_{j-1} + b \rfloor")




 is the same as
is the same as  (and the same for P and Q). Therefore, we can apply the spacing lemma with m=0 for 1≤j≤n: monotonicity of P and Q implies that R will be monotonic too. And that’s it: this proves that R is valid CDF for a distribution with total T. If we want the individual symbol frequencies, we can recover them as
(and the same for P and Q). Therefore, we can apply the spacing lemma with m=0 for 1≤j≤n: monotonicity of P and Q implies that R will be monotonic too. And that’s it: this proves that R is valid CDF for a distribution with total T. If we want the individual symbol frequencies, we can recover them as  .
.


 \\ f p_1 \end{pmatrix} = f \mathbf{p} + \begin{pmatrix} 1 - f \\ 0 \end{pmatrix}")
) \\ f p_1 + (1 - f) \end{pmatrix} = \begin{pmatrix} f p_0 \\ f p_1 + (1 - f) \end{pmatrix} = f \mathbf{p} + \begin{pmatrix} 0 \\ 1 - f \end{pmatrix}")
 \mathbf{e}_i")
 \mathbf{e}_{s_k}")
 ((1-u) \mathbf{e}_i + u\mathbf{1})")


") bits to encode a final state of x. Charles has already
bits to encode a final state of x. Charles has already )") coding operations, and still has some parallelism while doing so. This is not very exciting for a 2× or 4× interleaved coder, but for GPU applications N is typically on the order of 32 or 64, and at that level it’s definitely interesting.
coding operations, and still has some parallelism while doing so. This is not very exciting for a 2× or 4× interleaved coder, but for GPU applications N is typically on the order of 32 or 64, and at that level it’s definitely interesting.
















") and another pair
and another pair ") , how do we tell which one is better?
, how do we tell which one is better?


 (with at least one being nonzero). Sliding our straightedge until we hit a point corresponds to the minimization problem
(with at least one being nonzero). Sliding our straightedge until we hit a point corresponds to the minimization problem



 . Note it’s often useful to think of these quantities with units attached; we typically measure R in bits and [D] is whatever it is, so the unit of λ must be [λ] = bits/[D], i.e. λ is effectively an exchange rate that tells us how many units of distortion are worth as much as a single bit. We can then look at the R and D values of the solution we got back. If say we’re trying to hit a certain bit rate, then if R is close to that target, we might be happy and just stop. If R is way above the target bit rate, we overshot, and clearly need to penalize high distortions less; we might try another round with λ=0.1 next. Conversely, if say R is a few percent below the target rate, we might try another round with slightly higher lambda, say λ=1.02, trying to penalize distortion a bit more so we spend more bits to reduce it, and see if that gets us even closer.
. Note it’s often useful to think of these quantities with units attached; we typically measure R in bits and [D] is whatever it is, so the unit of λ must be [λ] = bits/[D], i.e. λ is effectively an exchange rate that tells us how many units of distortion are worth as much as a single bit. We can then look at the R and D values of the solution we got back. If say we’re trying to hit a certain bit rate, then if R is close to that target, we might be happy and just stop. If R is way above the target bit rate, we overshot, and clearly need to penalize high distortions less; we might try another round with λ=0.1 next. Conversely, if say R is a few percent below the target rate, we might try another round with slightly higher lambda, say λ=1.02, trying to penalize distortion a bit more so we spend more bits to reduce it, and see if that gets us even closer. and vary λ to taste to hit your targets. Often, you know enough about your problem space to have a pretty good idea of what values λ should have; for example, in video compression, it’s pretty common to tie the λ used when coding residuals to quantizer step size, based on the (known) behavior of the quantizer and the (expected) characteristics of real-world signals. But even when you don’t know anything about your data, you can always use a search process for λ as outlined above (which is, of course, slower).
and vary λ to taste to hit your targets. Often, you know enough about your problem space to have a pretty good idea of what values λ should have; for example, in video compression, it’s pretty common to tie the λ used when coding residuals to quantizer step size, based on the (known) behavior of the quantizer and the (expected) characteristics of real-world signals. But even when you don’t know anything about your data, you can always use a search process for λ as outlined above (which is, of course, slower). , which is a different but equivalent parameterization) scores. This gives you points on the lower left convex hull of the pareto frontier, which is what you want.
, which is a different but equivalent parameterization) scores. This gives you points on the lower left convex hull of the pareto frontier, which is what you want. with two Lagrange multipliers, with λ as before, and a second multiplier μ that encodes the exchange rate from time units into bits.
with two Lagrange multipliers, with λ as before, and a second multiplier μ that encodes the exchange rate from time units into bits.

 the “Kraft defect”. When K<0, the code has redundancy (i.e. there free code space left for assignment), for K=0 it is complete, and K>0 is over-complete (not uniquely decodable or using more code space than is available).
the “Kraft defect”. When K<0, the code has redundancy (i.e. there free code space left for assignment), for K=0 it is complete, and K>0 is over-complete (not uniquely decodable or using more code space than is available).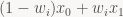

 is the 2D column vector we’re solving for, and the RHS vector of the pixel r values we can just call “r’.
is the 2D column vector we’re solving for, and the RHS vector of the pixel r values we can just call “r’.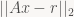 (2-norm), or equivalently
(2-norm), or equivalently 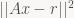 .
.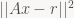 is quadratic; the way you find its minimum is by computing the derivative and equating it to 0, which leads us to what’s called the Normal Equations, which for this problem are
is quadratic; the way you find its minimum is by computing the derivative and equating it to 0, which leads us to what’s called the Normal Equations, which for this problem are
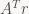 (and g and b as well) in the first pass, and also compute the entries of
(and g and b as well) in the first pass, and also compute the entries of 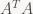 . To solve the system above, because we just have a 2×2 matrix, we can use Cramer’s rule to solve it directly, no need to mess around with factorizations or Gaussian Elimination or similar.
. To solve the system above, because we just have a 2×2 matrix, we can use Cramer’s rule to solve it directly, no need to mess around with factorizations or Gaussian Elimination or similar. turns into
turns into  ):
):  ,
,  , and
, and  . Note that all three values we’re summing only depend on wi, and wi is one of 4 possible values (depending on the index), so we can just precompute all of them. Also note they’re all quite small:
. Note that all three values we’re summing only depend on wi, and wi is one of 4 possible values (depending on the index), so we can just precompute all of them. Also note they’re all quite small:  .
.








